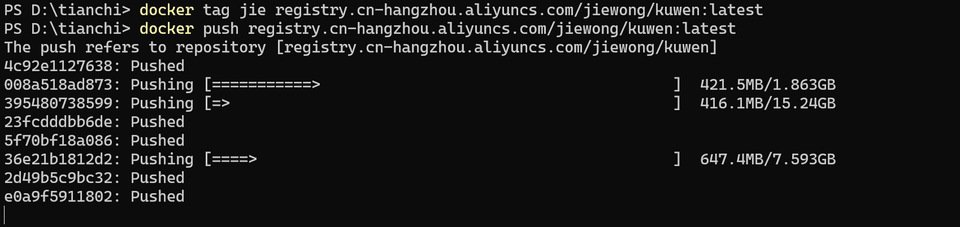
制作 docker 镜像
前言
在优酷x天池 「酷文」小说创作大模型挑战赛1的复赛中,需要提交复赛镜像。
容器镜像要求: 必须包含两个文件, /start.sh 和 /Dockerfile
/start.sh 为推理任务启动脚本,要求直接执行 /start.sh 后能够输出推理结果到 /tmp/result 目录。
/Dockerfile为容器镜像制作时使用的Dockerfile。
需要制作 docker 镜像
安装 Docker Desktop
云端的服务器环境大多数是 docker 或者虚拟化创建的,并不能直接在 docker 中运行 docker,所以要创作 docker 镜像需要在自己的电脑端创建。
- 下载并安装 docker desktop2
 登录账户
登录账户
 默认配置确定即可
默认配置确定即可
查看 docker desktop 版本
docker --version运行 hello world 测试
docker pull hello-worlddocker run hello-world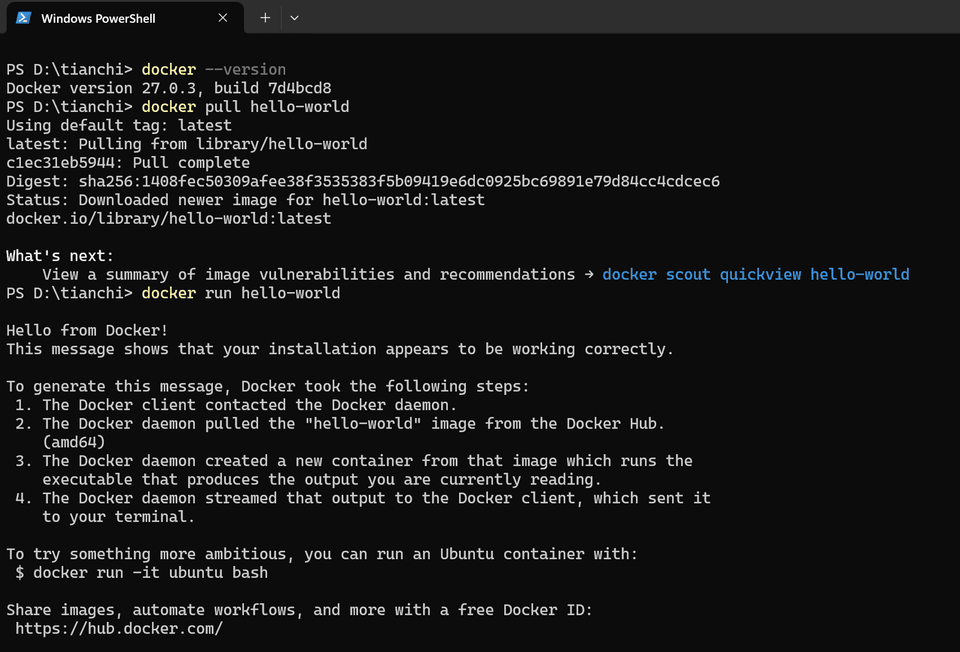
拉取云端资源
- Qwen2-7B-Instruct
- 微调权重
下载模型
这里用袁博士3开源的脚本4从 HuggingFace 镜像站5下载模型
D:\tianchi\hf_download.py
"""@File :hf_download.py@Description :Download huggingface models and datasets from mirror site.@Author :Xiaojian Yuan"""import argparseimport osimport sys
# Check if huggingface_hub is installed, if not, install ittry: import huggingface_hubexcept ImportError: print("Install huggingface_hub.") os.system("pip install -U huggingface_hub")
parser = argparse.ArgumentParser(description="HuggingFace Download Accelerator Script.")parser.add_argument( "--model", "-M", default=None, type=str, help="model name in huggingface, e.g., baichuan-inc/Baichuan2-7B-Chat",)parser.add_argument( "--token", "-T", default=None, type=str, help="hugging face access token for download meta-llama/Llama-2-7b-hf, e.g., hf_***** ",)parser.add_argument( "--include", default=None, type=str, help="Specify the file to be downloaded",)parser.add_argument( "--exclude", default=None, type=str, help="Files you don't want to download",)parser.add_argument( "--dataset", "-D", default=None, type=str, help="dataset name in huggingface, e.g., zh-plus/tiny-imagenet",)parser.add_argument( "--save_dir", "-S", default=None, type=str, help="path to be saved after downloading.",)parser.add_argument( "--use_hf_transfer", default=True, type=eval, help="Use hf-transfer, default: True")parser.add_argument( "--use_mirror", default=True, type=eval, help="Download from mirror, default: True")
args = parser.parse_args()
if args.use_hf_transfer: # Check if hf_transfer is installed, if not, install it try: import hf_transfer except ImportError: print("Install hf_transfer.") os.system("pip install -U hf-transfer -i https://pypi.org/simple") # Enable hf-transfer if specified os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1" print("export HF_HUB_ENABLE_HF_TRANSFER=", os.getenv("HF_HUB_ENABLE_HF_TRANSFER"))
if args.model is None and args.dataset is None: print( "Specify the name of the model or dataset, e.g., --model baichuan-inc/Baichuan2-7B-Chat" ) sys.exit()elif args.model is not None and args.dataset is not None: print("Only one model or dataset can be downloaded at a time.") sys.exit()
if args.use_mirror: # Set default endpoint to mirror site if specified os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" print("export HF_ENDPOINT=", os.getenv("HF_ENDPOINT")) # https://hf-mirror.com
if args.token is not None: token_option = "--token %s" % args.tokenelse: token_option = ""
if args.include is not None: include_option = "--include %s" % args.includeelse: include_option = "" if args.exclude is not None: exclude_option = "--exclude %s" % args.excludeelse: exclude_option = "" if args.model is not None: model_name = args.model.split("/") save_dir_option = "" if args.save_dir is not None: if len(model_name) > 1: save_path = os.path.join( args.save_dir, "models--%s--%s" % (model_name[0], model_name[1]) ) else: save_path = os.path.join( args.save_dir, "models--%s" % (model_name[0]) ) save_dir_option = "--local-dir %s" % save_path
download_shell = ( "huggingface-cli download %s %s %s --local-dir-use-symlinks False --resume-download %s %s" % (token_option, include_option, exclude_option, args.model, save_dir_option) ) os.system(download_shell)
elif args.dataset is not None: dataset_name = args.dataset.split("/") save_dir_option = "" if args.save_dir is not None: if len(dataset_name) > 1: save_path = os.path.join( args.save_dir, "datasets--%s--%s" % (dataset_name[0], dataset_name[1]) ) else: save_path = os.path.join( args.save_dir, "datasets--%s" % (dataset_name[0]) ) save_dir_option = "--local-dir %s" % save_path
download_shell = ( "huggingface-cli download %s %s %s --local-dir-use-symlinks False --resume-download --repo-type dataset %s %s" % (token_option, include_option, exclude_option, args.dataset, save_dir_option) ) os.system(download_shell)安装依赖
pip install --upgrade huggingface_hub下载 Qwen/Qwen2-7B-Instruct 模型
python hf_download.py --model Qwen/Qwen2-7B-Instruct --save_dir ./pretrainmodel文件
# 使用 CUDA 12 基础镜像FROM swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/pytorch/pytorch:2.3.0-cuda12.1-cudnn8-runtime
# 设置工作目录WORKDIR /
# 复制模型和 LoRA 文件到 Docker 容器中的指定位置COPY ./pretrainmodel /tmp/pretrainmodelCOPY ./lora /tmp/lora
# 复制 start.sh 文件到容器中COPY ./start.sh /start.sh
# 确保 start.sh 具有可执行权限RUN chmod +x /start.sh
# 设置容器启动时执行 start.shCMD ["/start.sh"]#!/bin/bash
# 设置设备device="cuda:0"
# 设置模型路径和LoRA路径model_path="/tmp/pretrainmodel/Qwen2-7B-Instruct"lora_path="/tmp/lora/Qwen2-7B-Instruct_novel_all/final"max_new_tokens=2048
# 创建结果目录result_dir="/tmp/result"mkdir -p $result_dir
# 运行Python脚本python3 - <<EOFimport jsonimport osfrom peft import LoraConfig, TaskType, get_peft_modelfrom transformers import AutoModelForCausalLM, AutoTokenizerimport torchfrom peft import PeftModel
device = "$device"
model_path = '$model_path'lora_path = "$lora_path"max_new_tokens = $max_new_tokens
stories = [ "现代都市与古代时空相交,一个现代女画家在画一幅古代风景画时,意外穿越到了画中所描绘的朝代,她不仅卷入了宫廷的争斗中,还发现了这幅画背后的惊人秘密。", "神秘岛屿生存冒险,一群来自现代社会的幸存��者在飞机失事后流落到一个未知岛屿,他们必须利用各自的知识和技能生存下去,同时解开岛上隐藏的古老秘密。", "现代奇幻背景,一个平凡的图书管理员偶然发现一本能预知未来的书,她如何利用这本书避免一场重大灾难,并揭示这本书的神秘来源与其背后的历史。", "现代都市背景,一个被束缚在重复、无趣生活中的普通白领,逐渐发现身边的一系列巧合和神秘事件与他自己创作的小说有着千丝万缕的联系,最终揭露出前世今生不可思议的秘密。", "古代背景,一个天资聪慧但性格古怪的谋士,通过看似不可能完成的任务逐渐赢得君主信任,在朝堂内外斗智斗勇,最终揭开宫廷深处的惊天大秘密的故事。", "未来都市背景,一群热爱科幻和玄幻的青少年,通过一次虚拟世界的探险,逐渐发现现实中的城市竟然隐藏着一个被遗忘的外星文明,他们如何与这个文明沟通并挽救危机的故事。", "中国古代背景,一个曾经的宫廷侍卫,被自己的朋友陷害而入狱,被指派一桩决定他生死的护卫任务,在过程中保护自己、寻找真相洗脱冤屈的故事。", "唐朝背景,一位身穿不凡的刺��客与被贬的公主携手合作,通过冒险和智慧,揭开朝廷内外重重阴谋,最终扭转乾坤并相伴一生的爱情故事。", "古代背景,一位边境小村的普通少年,在偶然目睹一场刺杀后,被卷入朝廷与江湖势力的斗争中,通过不断成长和历练,揭开自身惊人身世并扭转战局的惊险旅程。", "现代背景,一名退休侦探无法忍受平静的生活,他在一次老友聚会上接手了一桩谜团重重的老案件,运用他的经验和现代科技手段,最终破解了长达数十年的谜案,为受害者家属带来慰藉。"]
config = LoraConfig( task_type=TaskType.CAUSAL_LM, target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"], inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1)
# 加载tokenizertokenizer = AutoTokenizer.from_pretrained(model_path)
# 加载模型model = AutoModelForCausalLM.from_pretrained(model_path, device_map="cuda", torch_dtype=torch.bfloat16)
# 加载lora权重model = PeftModel.from_pretrained(model, model_id=lora_path, config=config)
# 创建结果目录result_dir = '$result_dir'os.makedirs(result_dir, exist_ok=True)
# 批处理函数def baseline_model(tasks, model): for idx, task in enumerate(tasks, start=1): task0 = "请创作一个包含复杂人物关系和情节反转的短篇故事。故事的主题是关于“" + task + "”。请确保故事包含至少四位主要角色,并设计出彼此之间复杂的关系。同时,故事要富有创意,避免使用常见的情节套路,并在结尾给出一个意想不到的反转。请确保字数在800字左右,语句通顺,结构完整。" count = 0 # 初始化计数器 discarded_count = 0 # 初始化抛弃计数器 messages = [ {"role": "system", "content": "You are a creative writer."}, {"role": "user", "content": task0} ] text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True) model_inputs = tokenizer([text], return_tensors="pt").to('cuda:0') results = [] while count < 50: # 只要计数器小于50,就继续生成 generated_ids = model.generate(input_ids=model_inputs.input_ids, max_new_tokens=max_new_tokens) generated_ids = [ output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids) ]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] if 750 <= len(response) <= 850: # 检查字数是否在750到850之间 data_to_write = { "instruction": "You are a creative writer.用起承转合的手法创作一篇700字左右小说。", "input": task, "output": response, } results.append(data_to_write) count += 1 # 更新计数器 else: discarded_count += 1 # 更新抛弃计数器 # 将结果写入文件 file_path = os.path.join(result_dir, f'prompt_{idx}_result.txt') with open(file_path, 'w', encoding='utf-8') as file: for result in results: json.dump(result, file, ensure_ascii=False) file.write('\n')
# 启动批处理存为jsonbaseline_model(stories, model)EOF构建 镜像
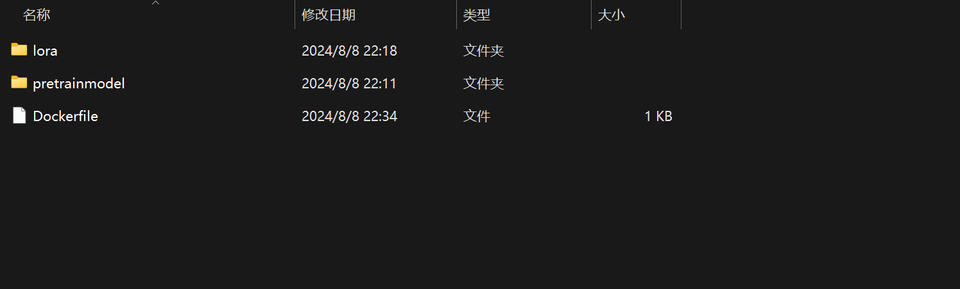
docker build -t your_image_name .
 在阿里云平台注册开通镜像服务6
登录
在阿里云平台注册开通镜像服务6
登录
docker login --username=abc registry.cn-hangzhou.aliyuncs.comabc 为阿里云账号全名,密码为开通服务时设置的密码。
可以在访问凭证页面修改凭证密码。
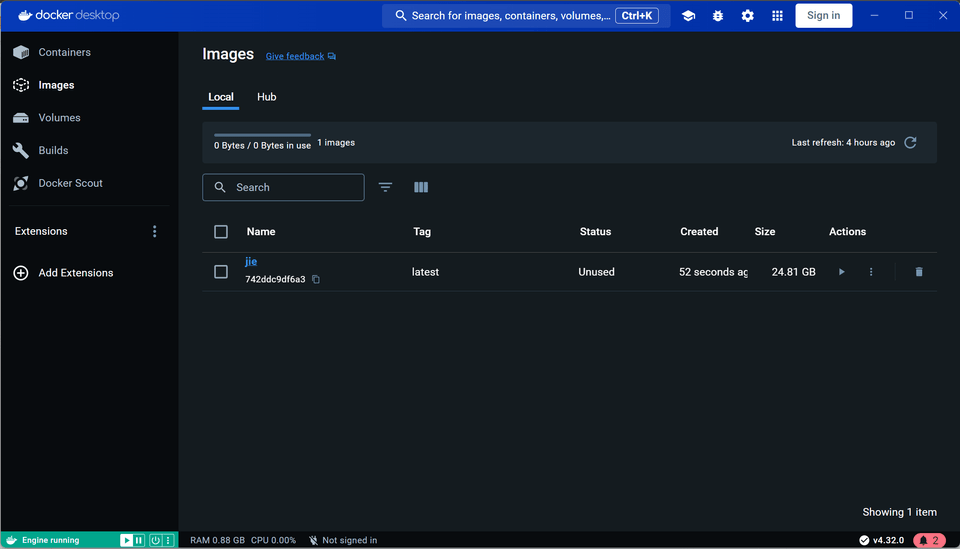 使用“docker tag”命令重命名镜像
使用“docker tag”命令重命名镜像
docker tag jie registry.cn-hangzhou.aliyuncs.com/jiewong/kuwen:latest推送至 Registry
push registry.cn-hangzhou.aliyuncs.com/jiewong/kuwen:latest